A大数据时代的语义技术(10116字)
1 大数据时代的语义数据环境
2 海量语义数据处理平台
3 语义技术在智慧城市与医学大数据方面的应用
4 小结
参考文献
B黄智生简历(741字)
医学知识图谱及其应用
黄智生教授个人简历
参考文献
大数据时代的语义技术
内容提要:
当前正处于大数据时代,大数据为智慧城市提供丰富的数据环境。智慧城市技术需要面向万维网大数据处理及其知识服务的支持。语义技术为海量数据处理及知识管理提供有效的技术手段。本文系统化介绍面向大数据环境的语义处理技术,包括大数据时代的语义数据环境、海量语义数据处理平台及语义技术在智慧城市与医学大数据中的应用。
关键词:
大数据 语义技术 知识图谱 知识管理智慧城市技术
中图分类号:
TP182
万维网为大数据时代提供海量的异构数据环境,进而为智慧城市技术及其知识服务提供巨大的开发空间。但是,数据异构性使我国面临如何对大数据进行有效语义整合和处理的巨大挑战。有效整合海量异构数据,其中一个核心主题就是如何实现异构数据的互操作(Interoperability)。
数据互操作指多源数据能够实现类似单一系统数据般的无缝链接。语义网思想及围绕语义网目标实现所开发的一系列技术,称为语义网技术,简称语义技术(Semantic Technology)。语义技术为异构数据提供数据互操作的技术基础,也为大数据的有效分析提供一种技术途径[1-3]。本文将系统化地介绍面向大数据环境的语义处理技术。
1 大数据时代的语义数据环境
1.1 语义技术的基本思想
面对海量的万维网数据,一个核心问题是如何快速有效地寻找所需信息。目前通用的办法是通过网络搜索引擎,采用键入对应的关键字来获得结果。但是,传统搜索引擎主要通过关键字对网络资源进行字符串匹配获取检索结果,易获得包含部分关键字的噪声数据。如检索“化学”,检索结果却出现“自动化学习”和“机械化学习”。为避免此类字符串误匹配,可通过对网络中的文本描述进行结构化处理,即采用专业词典,将长串文本描述进行分词处理,切割成独立的子部分。如把“自动化学习”切分成“自动化”和“学习”两个独立的部分,在使用“化学”进行查找时就不会匹配到“自动化学习”,因为需要满足同时匹配两个独立的子结构。将长串文本切分成子结构的处理方法称为结构化处理,但结构化处理不能实现数据互操作。在进行网络搜索使用的关键字只是表达语义上的需求,而并不在意网络资源是采用何种具体的词来表达。因此,需要一种网络资源描述方式,来刻画语义上的关联性。刻画某个特定领域的概念集合及该领域概念间的关联性被称为本体(Ontology)[4-5]。
近十多年,国际万维网组织制定和出台了一系列语义技术标准,得到广泛的应用。其中主要的语义技术标准包括以下四类。
(1)网络资源描述框架(ResourceDescription Framework,RDF)和网络资源描述框架模式(ResourceDescription Framework Scheme,RDFS)。主要用于描述网络信息资源,前者用于描述具体的网络信息资源及其对应概念,后者用于描述网络信息资源概念间的关联性。RDF/RDFS可以采用不同的数据格式表达,可被写成类似XML格式的文件。经常使用的RDF/RDFS表达格式是Ntriple三元组格式。
(2)网络本体语言(Web OntologyLanguage,OWL)。RDF/RDFS仅能描述网络信息资源及其相关概念的基本特征,但逻辑表达能力不强。OWL对RDF/RDFS的逻辑表达能力进行扩展,使之能够表达更复杂的逻辑关系,提供逻辑推理能力[5]。
(3)RDF查询语言SPARQL。SPARQL是一种针对RDF/RDFS语义数据的查询语言,也可用于OWL数据查询;若语义数据处理平台已嵌入对应的推理机,SPAROL还可用于对语义数据的推理结果查询。一个规范的语义数据处理平台通常会提供规范的SPAROL查询接口,被称为SPAROL服务端。
(4)规则交换格式(Rule InterchangeFormat,RIF)。RIF语言标准提供一种面向网络信息资源的高级规则知识表达能力,可弥补OWL对领域概念逻辑相关性描述的不足。
语义技术标准,建立在对网络信息资源进行数据连接的统一概念格式上,其主要概念表达方法是三元组(Triple)法,即将信息资源以类似主语、谓语和宾语结构来表达。为增强语义标示的唯一性,通过网络资源进行唯一性语义标定是语义技术的核心思想之一。所以,语义技术标准的基本作用是对网络资源进行描述,用于提供语义唯一标识,同时让数据内容独立于表达形式。
语义网(语义技术)的主要思想包括:(1)任何信息系统都需要数据;(2)数据表示要独立于具体的应用和平台,以保证最大程度的可重用性;(3)采用统一的数据概念表示,以保证数据表示独立于具体系统(可采用Triple/Tuple形式);(4)数据应能描述网络资源(要采用RDF/RDFS或其他类似的语言);(5)数据应提供初步推理支持(要采用OWL或其他知识表示语言)。值得注意的是RDF/RDFS/OWL均采用Triple语义模型。
1.2 现代信息系统的数据基础——关联语义数据云图
近十年,信息领域的重大进展之一是获得关联语义数据云图(Linked DataCloud),其中每个结点表示一个开放的数据源,结点间的弧表示数据源相互链接。截至2011年9月,关联语义数据云图已覆盖295个数据集、310亿条RDF语句、5.04亿个RDF链接(见图1)。其领域涵盖地理信息、生命科学、媒体、出版、政府信息、计算机与通信技术、工程学科、社会科学等。2011年6月,谷歌、雅虎和微软共同宣布推出新的语义搜索的技术标准;2012年5月,谷歌搜索引擎推出基于语义技术的知识图谱;截至2016年,关联语义数据云图的规模已经超过一张图所能表达的程度。
图1 关联语义数据云图
数据集均采用语义技术标准(RDF或者OWL形式)来表达,且绝大多数数据集是公开的,可以免费下载。由于采用国际语义技术标准与规范的本体工程技术开发方法,很容易将数据载入语义数据处理平台。关联语义数据云图的核心部分是维基百科,知识采用语义技术标准表达的数据DBpedia,其他领域数据集均可在语义上同维基百科的概念融合,其中Freebase是类似维基百科的数据集。2012年,谷歌以1亿美元购买Freebase,将其改造成知识图谱(knowledge graph)。
从形式上看,知识图谱采用语义技术形式表达系统化、结构化、集成化的特定领域知识结构,是面向万维网信息环境的重要的知识表达形式,是未来网络面向知识决策与分析的基础设施之一。知识图谱通常采用一种基于图的数据结构,旨在描述真实世界中存在的各种实体或概念,顶点表示实体或者概念,边代表实体与概念间的各种语义关系。从本质上看,知识图谱、语义数据集和本体没有根本性的区别;但是,知识图谱的构建更多地关注特定领域的基本事实。
庞大的语义数据集提供覆盖广泛领域的基础知识库,为信息系统开发提供全新的数据环境,是现代信息系统的数据基础。在大数据语义支撑环境下,可便捷地开发应用系统。
语义技术具有两大技术优势:(1)由于采用国际规范的数据表达格式,应用系统可方便地融合海量开源数据,节省前期数据准备工作,有利于未来系统功能的扩充;(2)由于采用面向语义表达的知识描述语言,使应用系统可方便地进行面向万维网环境的大数据处理,特别是进行知识提取和数据整合,代替现有的大量人工干预工作。
2 海量语义数据处理平台
通过关联语义数据云图,不仅可获得覆盖多领域的公开共享的海量数据,还可以使用一切采用语义技术标准描述的数据或者知识资源。由于采用面向语义的知识描述方式,使应用系统可实现更加智能化的面向知识表达和知识处理的各种服务。
面向语义数据存储和处理的系统称为三元组存储系统,统称TripleStore,类似于关系数据库。语义数据处理平台是三元组存储系统的功能扩展。当然,一个三元组存储系统的功能需求远超过关系数据库所能提供的支持,因为其需要适应面向知识处理和推理的能力需求,也需要提供规范的语义数据查询服务,即SPARQL服务端的支持。
2.1 海量语义数据处理平台一览
由于语义数据处理平台需要提供SPARQL查询服务端,需要一定的图数据处理能力。但传统面向SQL的关系数据库系统在提供SPARQL查询服务端时,效率不高。
下面是四种常用的语义数据处理平台或三元组存储系统。
(1)AllegroGraph是由Franz公司开发的面向语义数据处理的图数据库系统,其具备存储和处理数千亿级三元组的能力。同时还提供基于逻辑程序设计语言Prolog的RDFS++的推理能力。
(2)GraphDB是由OntoText公司开发的面向语义数据处理的图数据库系统。GraphDB是在OWLIM三元组存储系统基础上开发的,而OWLIM的前身是著名的RDF/RDFS数据存储与处理系统Sesame。
(3)LarKC是一个海量语义数据处理平台。LarKC是由欧盟第七研究框架语义技术重大项目LarKC团队开发的[6-8]。由于OntoText公司是LarKC的开发团队之一,所以LarKC的语义数据存储层采用OntoText公司的产品OWLIM[9]。LarKC提供灵活的存储系统嵌入形式,其三元组存储系统可方便地替换为其他规范的语义数据存储系统(如Virtuoso等)。
(4)Virtuoso被称为多源数据通用服务系统,由OpenLink软件公司开发。其支持数据类型既包括传统关系数据库(如RDBMS、ORDBMS、virtual database等),也包括语义数据、XML数据、自由文本数据和各类文件数据。因此,Virtuoso系统成为被广泛使用的语义数据处理平台之一。
虽然Virtuoso有许多明显的优越性,但是并非在各方面都比其他平台更强。应用时,可根据不同的环境选择不同的语义数据处理平台。对Virtuoso系统与LarKC平台进行比较,将二者优缺点进行归纳:(1)Virtuoso优点是被广泛使用、商业化支持、支持多种格式、可与数据库融合;缺点是系统响应时间慢,数据正确性要求比较高,非完全开源、非完全免费。(2)LarKC优点是系统响应时间快、数据正确性要求比较低、开源完全免费、支持自主设计工作流;缺点是参考资料少,无服务支持。
Virtuoso系统对数据的规范性和正确性要求比较高,如不允许语义数据包含断行符号的字符串;但LarKC支持字符串自由断行,便捷性更强。从系统的响应时间看,LarKC比Virtuoso要少一半。因此,LarKC的使用群体更多。
2.2 海量语义数据处理LarKC平台
LarKC是欧盟“第七研究框架计划的语义技术重大研究与开发项目”,旨在通过精准的知识分析和处理技术,开发海量语义数据处理与推理平台,使用户能有效地从海量数据中获取所需信息。为实现海量语义数据处理,LarKC采用组合的方法,即通过组合各种信息和知识的处理手段,灵巧地处理海量数据。从推理技术看,LarKC舍弃传统知识库推理机要求推理系统必须完全正确和完备的技术约束,引入非完备和非完全正确的推理技术,使之能应对语义网上海量语义数据的推理要求,主要通过下列两个特征来体现。
(1)可插拔(Pluggable)。LarKC平台采用来自信息处理领域的各种可能方法,如采用认知科学的启发式方法、有限理性的方法、经济学的成本/效益的权衡方法以及信息检索和数据库技术的各种技术方法。一个可插拔的体系结构将确保不同领域的计算方法可以连贯集成。
(2)分布式(Distributed)。LarKC平台支持采用云计算平台,并行计算与计算机集群平台等,其设计目标可扩展到大规模的分布式计算资源。
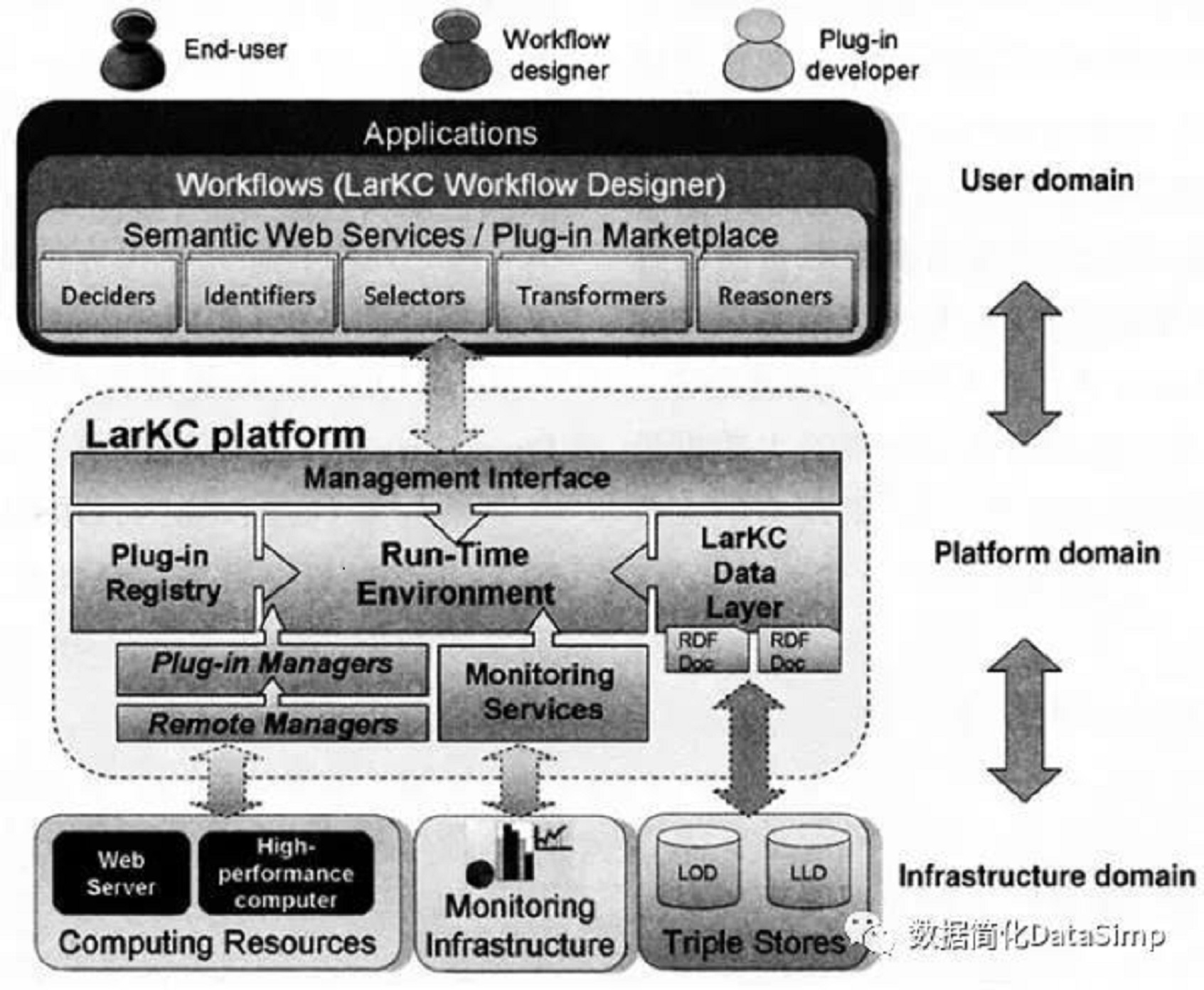
LarKC平台的体系结构如图2所示。该体系结构主要包括用户域(Userdomain)、平台域(Platformdomain)和基础结构域(Infrastructuredomain)。LarKC有三种类型的用户,插件开发者(Plug-in developer)、工作流设计者(Workflow designer)和使用者(End user)。针对不同类型的用户,提供不同的技术支持。如对于插件开发者,LarKC提供通过使用插件开发向导,对插件设计提供支持;工作流设计者,通过访问LarKC共享插件库来获得插件。LarKC平台提供工作流设计的可视化界面,帮助设计者提高工作流设计的效率。平台域提供插件开发和工作流设计所需的各种服务。LarKC核心层包括用于建立和管理有效数据流处理的数据层以及提供性能监测和评估的各种模块。
图2 LarKC平台的体系结构
LarKC平台成功启动后,LarKC平台管理界面可通过在浏览器输入“http://localhost:8182”进行访问。LarKC提供采用语义数据规范(即三元组格式)表达的工作流描述。其优点在于对于工作流本身也可以通过推理等进行深入分析和有效管理。
当工作流被提交后,即建立了一个SPARQL查询服务端,用户可通过该服务端进行规范的语义查询。LarKC平台已经嵌入了对于语义数据的基本推理(如RDF/RDFS和OWL的推理)的支持。
LarKC数据存储层可被替换成其他数据服务系统,如Virtuoso。所以,LarKC具备可吸纳和兼容其他语义数据存储系统的优点。目前,已有许多语义应用系统在LarKC平台上开发,主要集中在智能交通、智慧城市技术,以及生物医学大数据的应用方面[10]。
语义数据处理平台都会提供规范的语义数据查询服务端(SPARQL endpoint),使用户可以方便地对语义数据进行存储、处理和推理。
3 语义技术在智慧城市与医学大数据方面的应用
语义技术在大数据方面的应用例子很多,其应用领域覆盖智慧城市的各方面,如智能交通、智慧医疗、智慧能源与环境、智慧社区、智慧家居、财经与金融、新闻报道,及许多工程领域[10-11]。本文重点介绍语义技术在智慧城市方面的应用,特别是在智能交通与医学大数据方面的应用。
3.1 语义技术在智能交通方面的应用
智能交通是智慧城市的重要所需,所以欧盟第七框架语义技术重大课题LarKC选定的三个实例研究之一是智能交通与城市计算,即采用大数据技术针对现代化城市各种需求提供知识服务。采用LarKC平台开发智能交通与物联网相关的应用,主要有四种系统。
(1)意大利米兰交通预测系统。从该系统功能上看,类似于一般的汽车导航系统,即给定一个起点及目的地,系统能从路网信息中找出用时最短的行车路线。但与一般汽车导航系统不同,意大利米兰交通预测系统除能考虑季节、节假日和客流高峰时间等影响因素外,还能实时地从网络采集并分析该城市举行的大型活动对交通的潜在影响;同时,该系统还能从交通部门获得交通流的实时信息,并综合这些信息和知识进行智能化导航。
(2)韩国首尔路标管理系统(Road Sign Management,RSM)。该系统把首尔市的交通路标及其路网信息生成对应的语义数据集,能够有效地分析和发现路标中不符合韩国国家路标设置的规定(如在学校周围必须有警示牌等);同时,还能发现路牌中自相矛盾或者混乱信息的错误[12]。RSM使用的数据集来源包括开放街道地图数据OSM、韩国的POI地图数据、首尔市路标数据和关联地理数据。RSM系统总的语义数据规模达到了11亿个三元组。
(3)智能手机城市信息服务系统。该系统能提供地理环境信息和社交环境信息服务。该服务可通过用户智能手机的位置、视角并结合地理环境信息为用户推荐兴趣点。该系统能够成为智能化个人随身导游,根据所在地理位置,从对应的知识图谱中提供景点的解说,或提供对应的信息服务(如提供范围300米内的中餐馆信息服务等),是综合性的地理信息服务的知识图谱系统。
(4)智慧城市知识管理与分析系统。智慧城市的核心内容就是智能交通,智能交通系统的成功设计需要对群众的交通出行需求有充分的了解。智慧城市知识管理与分析系统中的一个基础模块就是手机使用者出行轨迹分析。该系统能够通过对手机轨迹的大数据分析,获得该地区人群出行需求。这些信息可用于智慧城市的宏观决策和智能交通的设计。
3.2 语义技术在医学大数据方面的应用
智慧健康与智能医疗也是智慧城市的重要内容之一。由于健康与医疗涉及大量医学知识及分析与推理,生命科学与医学已成为语义技术及知识图谱应用最广泛的领域。采用LarKC开发医学大数据应用,主要有四种系统。
(1)全基因组关联研究(Genome Wide Association Study,GWAS)。其是一种在人类全基因组范围内找出存在序列变异的基因分析技术。通过对比某种疾病的一组患者全基因组信息与对照组全基因组信息来确定某种病种与特定基因的关系,在一定程度上避免由先验概率的不准确性带来的误差。语义技术用于GWAS的基本切入点在于通过知识分析的手段来提高先验概率值的准确性。LarKC项目的全基因组关联研究的实验甚至做到对总数大概为1500万的SNP进行系统地分析,从而在很大程度上避免候选SNP的先验概率在经验估计上的偏差[13]。
(2)Openphacts药物研发平台。欧盟重大联合攻关项目Openphacts联合欧洲14家重要科研机构及8家药物研发公司,共斥资1600万欧元进行历时3年的面向药物研发的开放数据访问平台开发,其核心技术是采用语义技术为有关研究人员提供高效的数据访问技术环境的支持。Openphacts的设计目标是消除小分子药物发现的技术瓶颈,整合不同的数据源,建立标准与共同标识,提高药物研发工作流中的许多环节的效率,包括数据获取、处理、整合、互操作、可视化等。Openphacts药物研发平台的初期构建是建立在LarKC平台上,后来该系统被移植到商业化语义数据处理平台Virtuoso。
(3)临床实验知识管理与决策平台。SemanticCT是一个基于语义技术的临床试验知识管理与决策平台。其集成临床试验的数据、电子病历、药物知识库、医学指南等相关数据,构成对应的知识图谱,并载入LarKC平台,能够对海量临床试验提供有效知识管理和决策支持。如自动地从电子病历里推荐符合条件的、可参与临床试验的患者,以减少大量人工干预的过程,同时能够在临床试验的设计阶段,辅助推算临床试验准入条件的可行性[14]。
(4)医学指南更新知识服务系统。医学指南是由权威医学部门或组织制定的针对某种疾病或诊疗手段的系统化医学知识,主要用于指导医务工作者在具体的医学实践过程中采取最有效的治疗或护理措施。医学指南与医学教科书相比,具有更好的时效性和针对性;与医学论文相比,具有更强的系统性。所以,医学指南是医务人员和患者及其家属重要的参考材料之一,是重要的医学知识来源。循证医学指南对医学指南中各种描述及指导性意见,标注对应的科学证据。这些科学证据主要来源于医学领域的科技文献、研究成果等。由于大量新医学文献的涌现,为使得医学指南知识能够覆盖最新的医学研究成果,须考虑医学指南知识的及时更新服务。医学指南更新知识服务系统建立在LarKC平台上,该系统采用自然语言处理工具及本体技术,抽取指南描述中UMLS和SNOMED CT对应术语,引进语义距离计算处理以及综合评估方法,对抽取处理的关键词进行排序,逐步获得最佳相关证据集[15]。
4 小结
语义技术的一系列技术标准,采用独立于具体应用系统的统一数据表达格式,使得基于语义技术的应用系统可以非常方便地融合网络大量共享数据。如语义数据关联云图,既便于融合他人现有数据,也有利于未来系统功能的扩充。
语义技术采用面向知识提取和知识表达的技术方式,更接近于人类的知识表达方式,使用户可以方便地审核知识表达的正确性,同时也可以代替现有大量的人工干预工作。由于引入知识处理,也提高了处理问题的精度和效率。由于语义技术提供知识管理与推理的能力,使开发的应用系统能够针对海量的数据进行宏观把握,提供有效的决策支持。大量应用系统的成功经验证明,语义技术及其知识图谱技术必将在大数据时代发挥不可替代的作用。
参考文献
[1]BERNERS-LEET,HENDELER J.Publishing on the Semantic Web[J].Nature,2001(4):1023-1025.
[2]BERNERS-LEET,HENDELER J,LASSILA O.The Semantic Web[J].Scientific AmericanMagazine,2001:29-37.
[3]FEIGENBAUML,HERMAN I,HONGSERMEIER T,et al.The Semantic Web in action[J].ScientificAmerican,2007,297(12):64-71.
[4]SHADBOLTN,HALL W,BERNERS-LEE T.The Semantic Web revisited[J].IEEE IntelligentSystems,2006(5/6):96-101.
[5]MCGUINNESSD L,HARMELEN F V.OWL web ontology language[EB/OL].(2004-02-10)[2016-08-01].http://www.w3.org/TR/owl-features/.
[6]FENSELD,HARMELEN E Unifying reasoning and search to web scale[J].IEEE InternetComputing,2007,11(2):94-96.
[7]FENSELD,HARMELEN F,SCHOOLER L,et al.Towards LarKC:a platform for web-scale reasoning[C]//IEEEInternational Conference on Semantic Computing.New York:IEEEPress,2008:524-529.
[8]ASSELM,CHEPTSOV A,GALLIZO G,et al.Large Knowledge Collider:a service-orientedplatform for large-scale semantic reasoning[C]//Proceedings of the InternationalConference on Web Intelligence,Mining and Semantics(WIMS' 11).ACM InternationalConference Proceedings Series.Sogndal:2011.
[9]KIRYAKOVA,OGNYANOV D,MANOV D.OWLIM-a pragmatic semantic repository forOWL[C]//Proceedings of Int.Workshop on Scalable Semantic Web Knowledge BaseSystems(SSWS 2005).LNCS,Berlin:Springer,2005:182-192.
[10]李劲松,黄智生.生物医学语义技术[M].杭州:浙江大学出版社,2012.
[11]FENSELD,HARMELEN F V,ANDERSSON B,et al.Towards LarKC:a platform for Web-scalereasoning[C]//Proceedings of the 2nd IEEE International Conference on SemanticComputing.IEEEICSC,Washington:IEEE Press,2008:524-529.
[12]LEE T,PARKS,HUANG Z S,et al.Toward Seoul road sign management on the LarKCplatform[C]//Proceedings of the 9th International Semantic WebConference(ISWC2010).Track of Posters and Demos,2010.
[13]AngusRoberts,Mark Greenwood,Danica Damljanovic,Hamish Cunningham,MattiasJohannson,and James McKay.D7b.3.1a version 1 iteration report.Technicalreport,LarKC project deliverable,2009.
[14]HUANG ZS,TEIJE A D,HARMELEN F V.SemanticCT:a semantically enabled system for clinicaltrials[EB/OL].[2016-09-01].https://www.researchgate.net/publication/237072662_SemanticCT_A_SemanticallyEnabled_System_for_Clinical_Trials.
黄智生简历
医学知识图谱及其应用
Medical Knowledge Graphs and Applications
荷兰阿姆斯特丹自由大学人工智能系
首都医科大学大脑保护高精尖中心
武汉科技大学大数据研究院
知识图谱是面向大数据环境能够集成各种知识资源的新型知识表达形式。知识图谱通过描述特定领域的概念和实体及其语义关系来构成大规模的语义知识网络。医学知识图谱能够集成医学的各类知识与数据资源,从而为临床医生提供临床决策支持。我们将介绍医学知识图谱的一系列基础技术。在此基础上,我们将进一步介绍医学知识图谱的具体应用,包括抑郁症知识图谱及其临床使用,以及自杀知识图谱用于网络自杀救助的应用实例。
黄智生教授个人简历
黄智生博士,荷兰阿姆斯特丹自由大学人工智能系终身教授,首都医科大学大脑保护高精尖中心抑郁症人工智能创新团队首席科学家,武汉科技大学大数据研究院副院长和特聘教授,北京工业大学等六所大学或机构的兼职教授。出版了《海量语义数据处理-平台,技术,与应用》《生物医学语义技术》等教材,发表过论文论著超过二百篇,担任超过一百个国际学术会议的程序委员会委员,超过二十个国际会议的联合主席,担任六个国际学术刊物的编委,特约主编或特约编委。主持欧盟第七框架重大项目LarKC中推理工作组的工作。主持欧盟第七框架智慧医疗重大项目EURECA中基于语义技术的临床试验系统SemanticCT的开发;主持了基于语义技术的抗菌药物合理用药系统SeSRUA的开发。他参与开发的E-Culture项目在2006年世界语义万维网技术挑战赛上获得冠军。作为第一作者获得2014世界健康信息技术学术年会(HealthInfo2014)最佳论文奖。
参考文献
1.黄智生.大数据时代的语义技术.[EB/OL];数字图书馆论坛,http://www.cssn.cn/glx_tsqbx/201706/t20170622_3557879.shtml,2017-06-22.